Your AI,
Your Machine,
Your Rules
Unleash the full potential of your hardware, from MacBooks to DGX Spark.
Run local inference, manage agents, and cluster resources seamlessly.
One app, infinite possibilities.
Free forever · No account required · Your data stays local
Complete AI Orchestration
Backend.AI GO scales with your needs.
Local Inference Engine
Run llama.cpp, mlx-lm, and stable-diffusion.cpp natively on Windows, macOS, Linux, and personal workstations like DGX Spark. Hardware acceleration for CUDA, ROCm, Metal, and Intel Arc.
Personal AI Agents
Built-in Chat, Image Generation, and Agent capabilities with Tool Calling and MCP (Model Context Protocol) for secure personal tasks.
P2P Clustering
Connect up to 32 Backend.AI GO instances to create a personal compute cluster, or join enterprise Backend.AI clusters.
Cloud & Remote Model Integration
Seamlessly integrate OpenAI, Anthropic, Gemini, or connect to remote vLLM/Ollama servers as if they were local.
Security & Privacy
Your data stays with you. Run sensitive workloads locally without data leaving your infrastructure.
Service Router
Expose all your local, cluster, and cloud AI resources through a single, unified API endpoint.
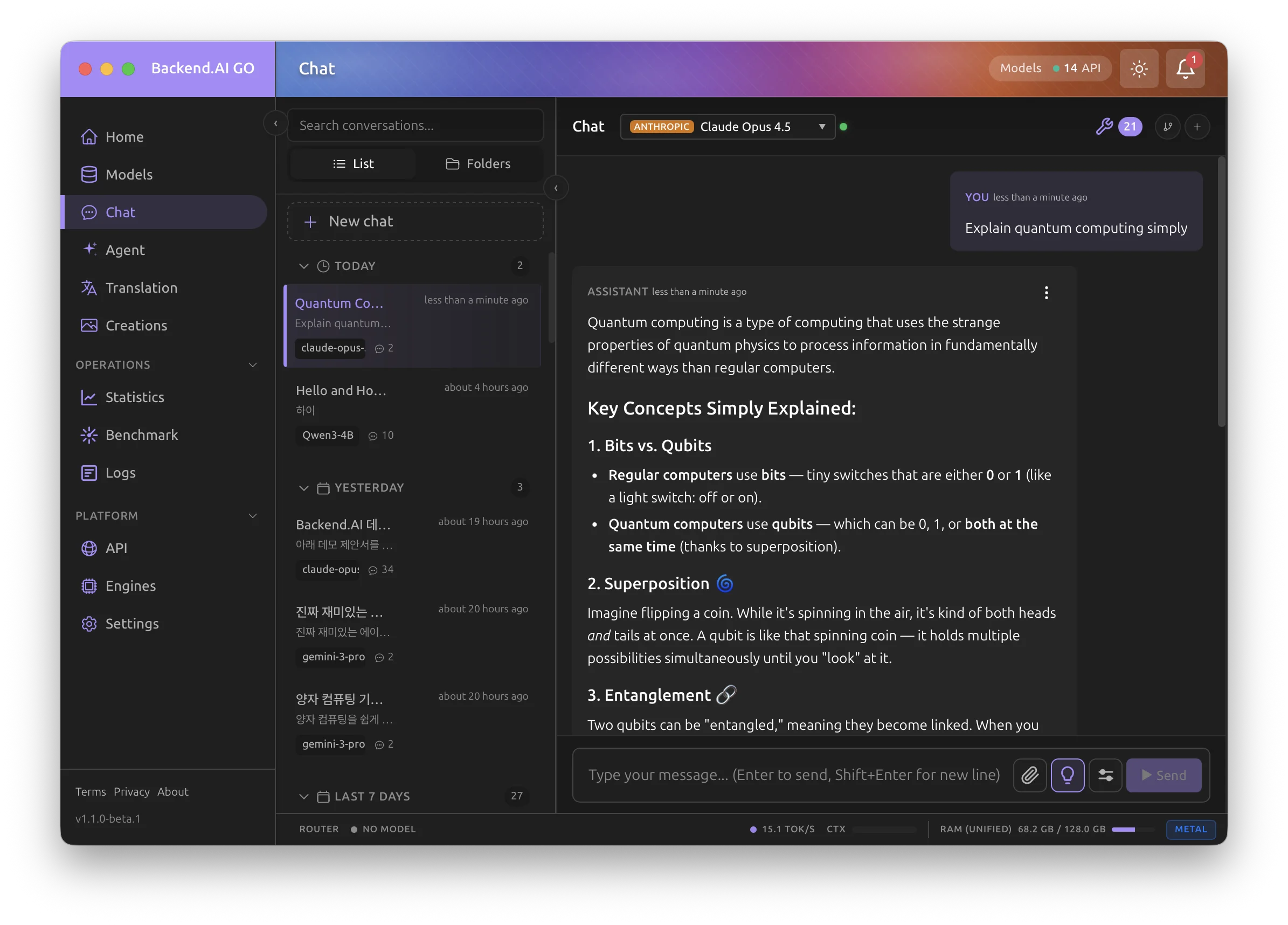
See It in Action
A modern interface for local AI.
Download Backend.AI:GO for desktop
Latest version v1.4.1
Install with one command
macOS Apple Silicon
Requires Homebrew. The cask is automatically updated with each stable release.
Backend.AI GO Enterprise
Built for organizations
Air-gapped model & software update servers, custom-branded builds, unified routing across your organization, and seamless integration with Backend.AI Enterprise clusters for large-scale centralized AI operations. Also available as part of the PALI suite.
Contact Us